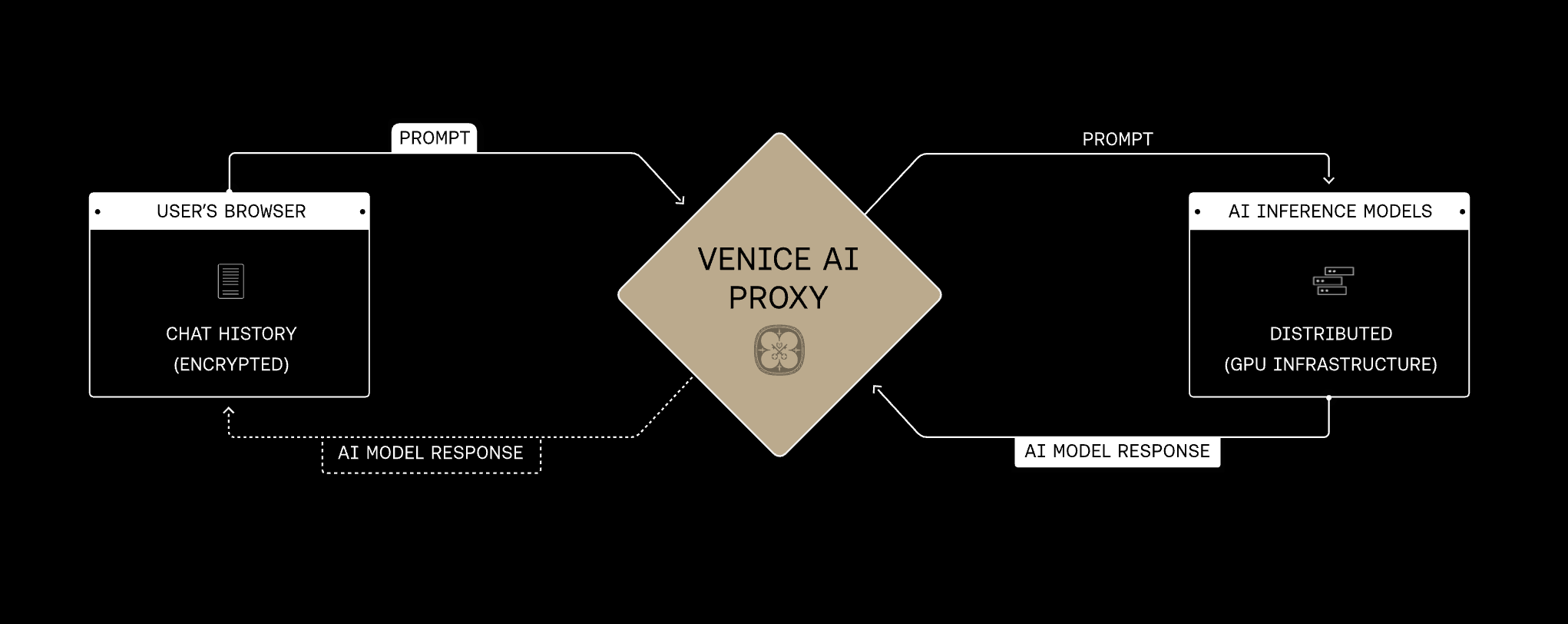
 ## Privacy architecture
The Venice proxy is the shared foundation for every privacy mode. Requests pass through Venice over HTTPS/TLS and are relayed without Venice storing prompt or response content. The privacy mode on the selected model determines what happens next at the provider or model runtime layer.
Venice presents model privacy in four modes. They build on the same proxy foundation and add progressively stronger protections, from obscuring identity from the provider to encrypting prompts end-to-end into a verified enclave.
## Privacy architecture
The Venice proxy is the shared foundation for every privacy mode. Requests pass through Venice over HTTPS/TLS and are relayed without Venice storing prompt or response content. The privacy mode on the selected model determines what happens next at the provider or model runtime layer.
Venice presents model privacy in four modes. They build on the same proxy foundation and add progressively stronger protections, from obscuring identity from the provider to encrypting prompts end-to-end into a verified enclave.
Venice proxies the request without sending your Venice identity to the model provider. Prompt content is still visible to that provider.
Prompt and response content is processed for inference only and is not retained after the request completes.
Supported models run inside a Trusted Execution Environment with remote attestation support.
Your client encrypts the prompt before sending it. Venice relays ciphertext, and only the verified TEE decrypts it.