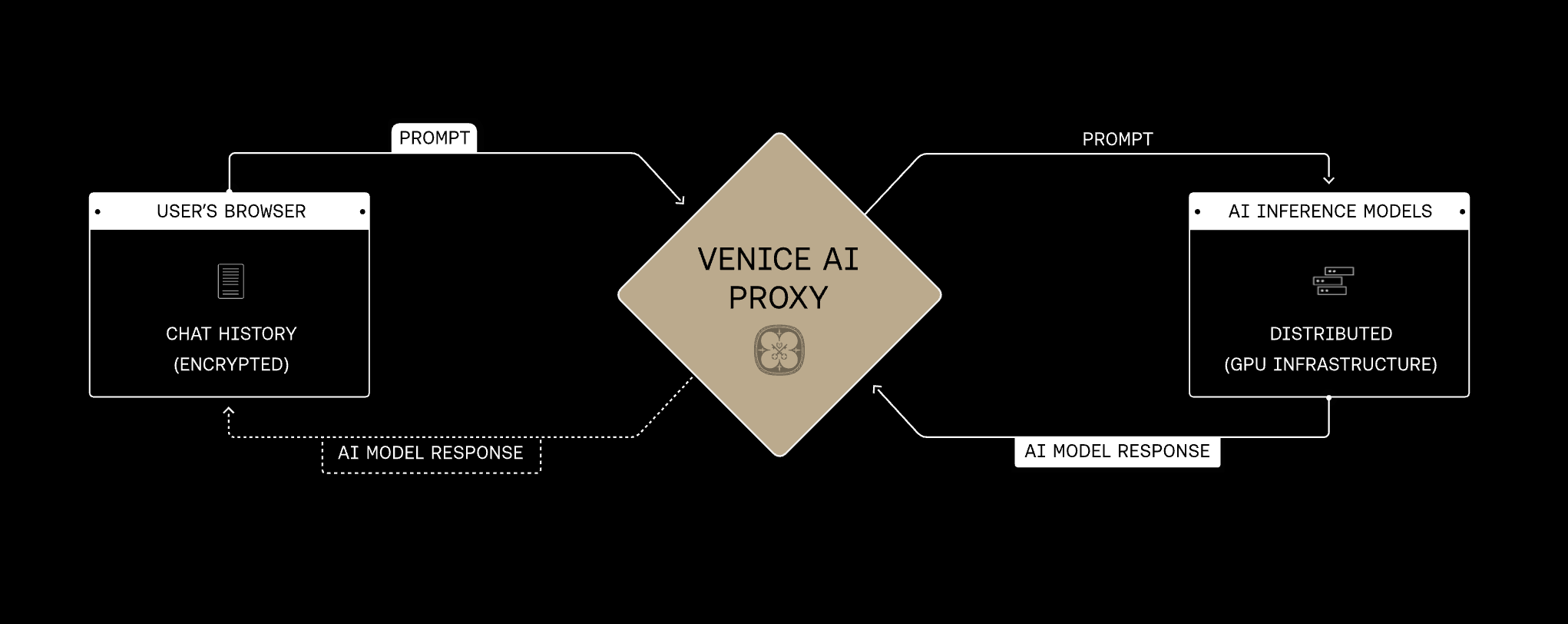
La única forma de lograr una privacidad razonable del usuario es evitar recopilar esta información en primer lugar. Esto es más difícil desde el punto de vista de la ingeniería, pero creemos que es el enfoque correcto.La API de Venice replica la misma arquitectura de privacidad de backend que la plataforma Venice: las solicitudes pasan por el proxy de Venice a través de conexiones cifradas, Venice no almacena ni registra el contenido de los prompts y las respuestas para la inferencia normal, y cada modelo seleccionado añade uno de cuatro modos de privacidad en la capa de runtime: Anonymous, Private, TEE o E2EE.
Arquitectura de privacidad
El proxy de Venice es la base compartida para cada modo de privacidad. Las solicitudes pasan por Venice a través de HTTPS/TLS y se retransmiten sin que Venice almacene el contenido de prompt o respuesta. El modo de privacidad del modelo seleccionado determina qué sucede a continuación en la capa del proveedor o del runtime del modelo. Venice presenta la privacidad de los modelos en cuatro modos. Se construyen sobre la misma base de proxy y añaden protecciones progresivamente más fuertes, desde ocultar la identidad al proveedor hasta cifrar prompts de extremo a extremo dentro de un enclave verificado.Protección de privacidad creciente
Anonymous
Identidad oculta al proveedor
Venice enruta la solicitud sin enviar tu identidad de Venice al proveedor del modelo. El contenido del prompt sigue siendo visible para ese proveedor.
Private
Cero retención de datos, aplicado por contrato
El contenido del prompt y de la respuesta se procesa únicamente para inferencia y no se retiene una vez que la solicitud se completa.
TEE
Inferencia aislada por hardware
Los modelos compatibles se ejecutan dentro de un Trusted Execution Environment con soporte de atestación remota.
E2EE
Cifrado de extremo a extremo hacia un TEE verificado
Tu cliente cifra el prompt antes de enviarlo. Venice retransmite el texto cifrado, y solo el TEE verificado lo descifra.
/models te indica el nivel de privacidad de cada modelo. Los modelos marcados como anonymized son modelos Anonymous, y los modelos marcados como private son modelos Private. TEE y E2EE se muestran por separado en las capacidades del modelo, como supportsTeeAttestation y supportsE2EE.
Para más detalles de implementación, consulta la guía de modelos TEE y E2EE.
TEE y E2EE
Los modelos TEE y E2EE añaden controles criptográficos y respaldados por hardware sobre el enfoque predeterminado de Venice de no retención de contenido.Usa TEE cuando
Quieras que el modelo se ejecute dentro de un enclave de hardware atestado, pero tu cliente pueda enviar prompts en texto claro a través de la solicitud normal a la API.
Usa E2EE cuando
Quieras prompts cifrados antes de que salgan de tu cliente y descifrados solo dentro de un TEE verificado.
/chat/completions con modelos con capacidad E2EE. Tu cliente debe obtener la atestación, verificar el nonce y la evidencia del enclave, cifrar los mensajes user y system, enviar las cabeceras X-Venice-TEE-*, transmitir la respuesta en streaming y verificar/descifrar el contenido de la respuesta.
E2EE también desactiva funciones que necesitan texto claro fuera del enclave, como búsqueda web, memoria, resúmenes, algunos flujos de herramientas y otros procesamientos del lado del servidor.
Elegir un modelo
Usa/models para ver qué protecciones de privacidad admite cada modelo antes de enviar una solicitud.
Cada modelo tiene dos campos relevantes:
model_spec.privacyte indica el modo de privacidad base del modelo:anonymized: Venice oculta tu identidad al proveedor, pero este aún puede ver el prompt.private: Venice enruta la solicitud a través de infraestructura con cero retención de datos.
model_spec.capabilitieste indica si el modelo admite protecciones más fuertes:supportsTeeAttestation: el modelo puede ejecutarse dentro de un Trusted Execution Environment verificable.supportsE2EE: el modelo puede aceptar prompts cifrados por el cliente que se descifran solo dentro del TEE.
private para cero retención de datos, elige tee: true para aislamiento respaldado por hardware y elige e2ee: true cuando necesites que los prompts se cifren antes de salir de tu cliente.