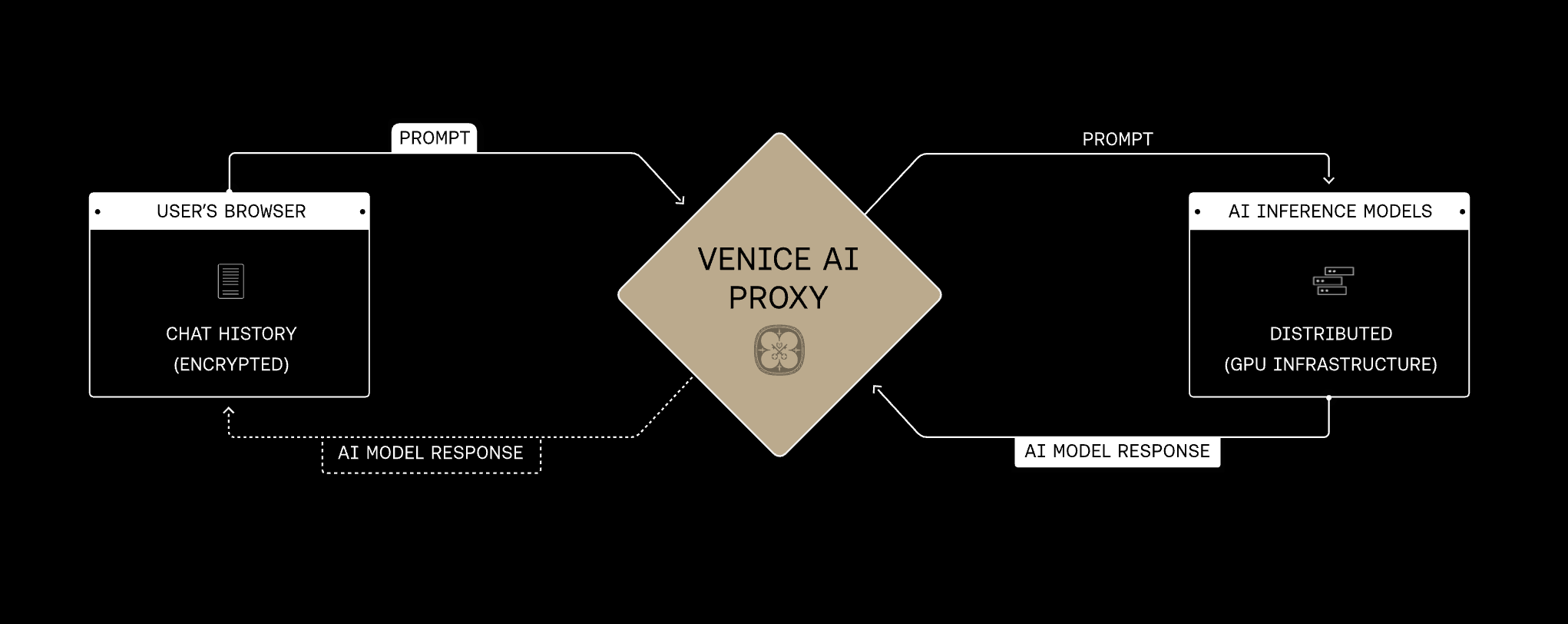
A única forma de alcançar privacidade razoável do usuário é evitar coletar essas informações em primeiro lugar. Isso é mais difícil de fazer do ponto de vista de engenharia, mas acreditamos que é a abordagem correta.A API Venice replica a mesma arquitetura de privacidade de backend da plataforma Venice: as requisições passam pelo proxy Venice por conexões criptografadas, a Venice não armazena nem registra o conteúdo de prompts e respostas para inferência normal, e cada modelo selecionado adiciona um dos quatro modos de privacidade na camada de runtime: Anonymous, Private, TEE ou E2EE.
Arquitetura de privacidade
O proxy Venice é a fundação compartilhada para todos os modos de privacidade. As requisições passam pela Venice por HTTPS/TLS e são repassadas sem que a Venice armazene o conteúdo do prompt ou da resposta. O modo de privacidade do modelo selecionado determina o que acontece em seguida na camada do provedor ou do runtime do modelo. A Venice apresenta a privacidade do modelo em quatro modos. Eles se baseiam na mesma fundação de proxy e adicionam proteções progressivamente mais fortes, desde ocultar a identidade do provedor até criptografar prompts de ponta a ponta em um enclave verificado.Aumento da proteção de privacidade
Anonymous
Identidade oculta do provedor
A Venice faz proxy da requisição sem enviar sua identidade Venice ao provedor do modelo. O conteúdo do prompt ainda é visível para esse provedor.
Private
Retenção zero de dados, garantida contratualmente
O conteúdo do prompt e da resposta é processado apenas para inferência e não é retido após a conclusão da requisição.
TEE
Inferência isolada por hardware
Modelos compatíveis são executados dentro de um Trusted Execution Environment com suporte a atestação remota.
E2EE
Criptografia ponta a ponta para um TEE verificado
Seu cliente criptografa o prompt antes de enviar. A Venice repassa o texto cifrado, e somente o TEE verificado o decifra.
/models informa o nível de privacidade de cada modelo. Modelos marcados como anonymized são modelos Anonymous, e modelos marcados como private são modelos Private. TEE e E2EE são mostrados separadamente nas capacidades do modelo, como supportsTeeAttestation e supportsE2EE.
Para detalhes de implementação, veja o guia de modelos TEE e E2EE.
TEE e E2EE
Modelos TEE e E2EE adicionam controles criptográficos e baseados em hardware sobre a abordagem padrão de não retenção de conteúdo da Venice.Use TEE quando
Você quer que o modelo seja executado dentro de um enclave de hardware atestado, mas seu cliente pode enviar prompts em texto claro pela requisição normal da API.
Use E2EE quando
Você quer que os prompts sejam criptografados antes de saírem do seu cliente e decifrados apenas dentro de um TEE verificado.
/chat/completions com modelos compatíveis com E2EE. Seu cliente deve buscar a atestação, verificar o nonce e a evidência do enclave, criptografar as mensagens user e system, enviar os cabeçalhos X-Venice-TEE-*, fazer streaming da resposta e verificar/decifrar o conteúdo da resposta.
E2EE também desabilita recursos que precisam de texto claro fora do enclave, como busca na web, memória, resumos, alguns fluxos de ferramentas e outros processamentos do lado do servidor.
Escolhendo um modelo
Use/models para ver quais proteções de privacidade cada modelo suporta antes de enviar uma requisição.
Cada modelo tem dois campos relevantes:
model_spec.privacyinforma o modo de privacidade base do modelo:anonymized: A Venice oculta sua identidade do provedor, mas o provedor ainda pode ver o prompt.private: A Venice roteia a requisição por infraestrutura com retenção zero de dados.
model_spec.capabilitiesinforma se o modelo suporta proteções mais fortes:supportsTeeAttestation: o modelo pode ser executado dentro de um Trusted Execution Environment verificável.supportsE2EE: o modelo pode aceitar prompts criptografados pelo cliente que são decifrados somente dentro do TEE.
private para retenção zero de dados, escolha tee: true para isolamento baseado em hardware e escolha e2ee: true quando precisar que os prompts sejam criptografados antes de saírem do seu cliente.