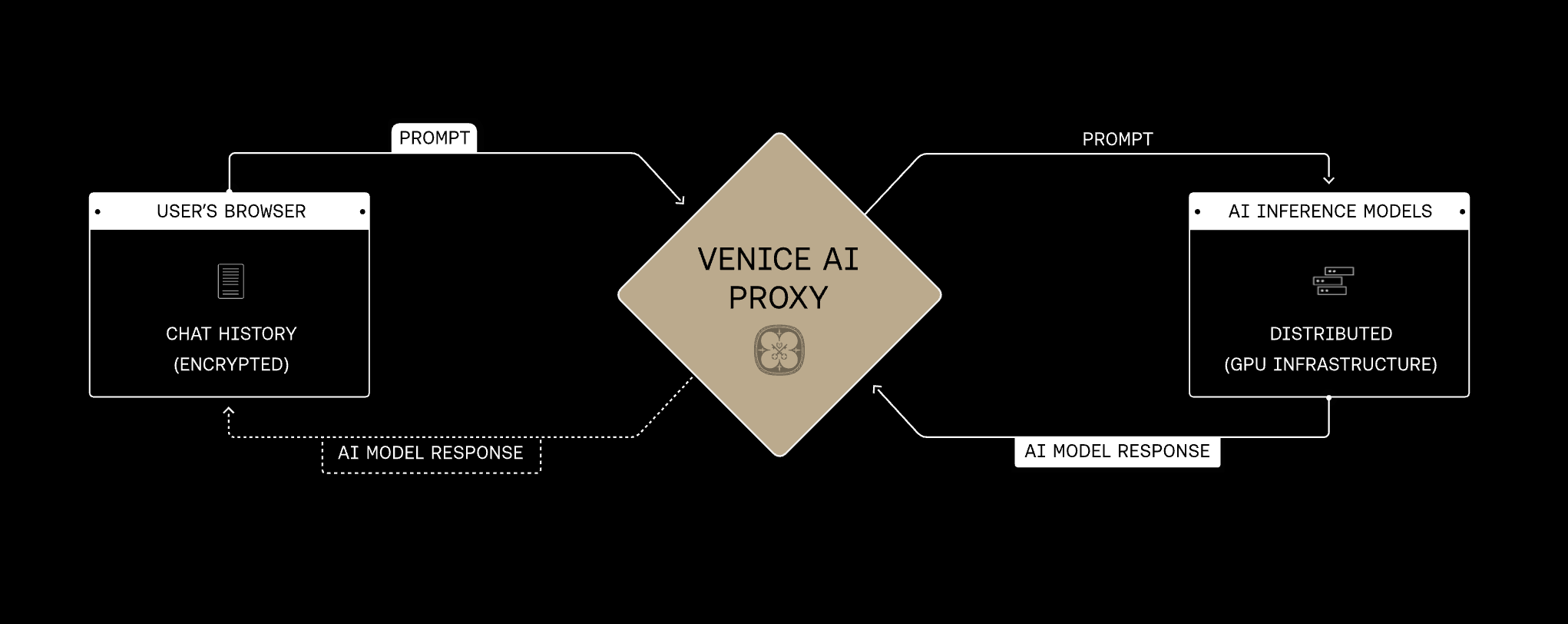
Le seul moyen d’atteindre une confidentialité utilisateur raisonnable est d’éviter de collecter ces informations en premier lieu. C’est plus difficile à faire d’un point de vue ingénierie, mais nous pensons que c’est la bonne approche.L’API Venice réplique la même architecture de confidentialité backend que la plateforme Venice : les requêtes passent par le proxy Venice sur des connexions chiffrées, Venice ne stocke ni ne journalise le contenu des prompts et des réponses pour l’inférence normale, et chaque modèle sélectionné ajoute l’un des quatre modes de confidentialité au niveau du runtime : Anonymous, Private, TEE ou E2EE.
Architecture de confidentialité
Le proxy Venice est le fondement partagé de chaque mode de confidentialité. Les requêtes passent par Venice via HTTPS/TLS et sont relayées sans que Venice stocke le contenu des prompts ou des réponses. Le mode de confidentialité du modèle sélectionné détermine ce qui se passe ensuite au niveau du fournisseur ou du runtime du modèle. Venice présente la confidentialité des modèles en quatre modes. Ils s’appuient sur la même fondation proxy et ajoutent des protections progressivement plus fortes, allant de l’obscurcissement de l’identité face au fournisseur jusqu’au chiffrement de bout en bout des prompts dans une enclave vérifiée.Protection de confidentialité croissante
Anonymous
Identité masquée au fournisseur
Venice transmet la requête sans envoyer votre identité Venice au fournisseur du modèle. Le contenu du prompt reste visible pour ce fournisseur.
Private
Zéro rétention de données, garantie par contrat
Le contenu du prompt et de la réponse est traité uniquement pour l’inférence et n’est pas conservé après la fin de la requête.
TEE
Inférence isolée matériellement
Les modèles pris en charge s’exécutent à l’intérieur d’un Trusted Execution Environment avec prise en charge de l’attestation à distance.
E2EE
Chiffrement de bout en bout vers un TEE vérifié
Votre client chiffre le prompt avant de l’envoyer. Venice relaie le texte chiffré, et seul le TEE vérifié le déchiffre.
/models vous indique le niveau de confidentialité de chaque modèle. Les modèles marqués anonymized sont des modèles Anonymous, et les modèles marqués private sont des modèles Private. TEE et E2EE sont affichés séparément dans les capacités du modèle, telles que supportsTeeAttestation et supportsE2EE.
Pour les détails d’implémentation, voir le guide des modèles TEE et E2EE.
TEE et E2EE
Les modèles TEE et E2EE ajoutent des contrôles cryptographiques et matériels par-dessus l’approche par défaut de non-rétention de contenu de Venice.Utilisez TEE quand
Vous voulez que le modèle s’exécute à l’intérieur d’une enclave matérielle attestée, mais votre client peut envoyer des prompts en clair via la requête API normale.
Utilisez E2EE quand
Vous voulez que les prompts soient chiffrés avant de quitter votre client et déchiffrés uniquement à l’intérieur d’un TEE vérifié.
/chat/completions avec des modèles compatibles E2EE. Votre client doit récupérer l’attestation, vérifier le nonce et les preuves d’enclave, chiffrer les messages user et system, envoyer les en-têtes X-Venice-TEE-*, streamer la réponse et vérifier/déchiffrer le contenu de la réponse.
E2EE désactive également les fonctionnalités qui nécessitent du texte en clair en dehors de l’enclave, telles que la recherche web, la mémoire, les résumés, certains flux d’outils et d’autres traitements côté serveur.
Choisir un modèle
Utilisez/models pour voir quelles protections de confidentialité chaque modèle prend en charge avant d’envoyer une requête.
Chaque modèle a deux champs pertinents :
model_spec.privacyvous indique le mode de confidentialité de base du modèle :anonymized: Venice masque votre identité au fournisseur, mais le fournisseur peut toujours voir le prompt.private: Venice route la requête à travers une infrastructure zéro rétention de données.
model_spec.capabilitiesvous indique si le modèle prend en charge des protections plus fortes :supportsTeeAttestation: le modèle peut s’exécuter à l’intérieur d’un Trusted Execution Environment vérifiable.supportsE2EE: le modèle peut accepter des prompts chiffrés côté client qui ne sont déchiffrés qu’à l’intérieur du TEE.
private pour zéro rétention de données, choisissez tee: true pour une isolation matérielle, et choisissez e2ee: true lorsque vous avez besoin que les prompts soient chiffrés avant de quitter votre client.