Der einzige Weg, einen vernünftigen Datenschutz zu erreichen, besteht darin, diese Informationen gar nicht erst zu erfassen. Das ist aus technischer Sicht schwieriger, aber wir sind überzeugt, dass es der richtige Ansatz ist.Die Venice API repliziert dieselbe Backend-Datenschutzarchitektur wie die Venice-Plattform: Anfragen laufen über verschlüsselte Verbindungen durch den Venice-Proxy, Venice speichert oder protokolliert für normale Inferenz weder Prompt- noch Antwortinhalte, und jedes ausgewählte Modell fügt auf der Laufzeitebene einen von vier Datenschutzmodi hinzu: Anonymous, Private, TEE oder E2EE.
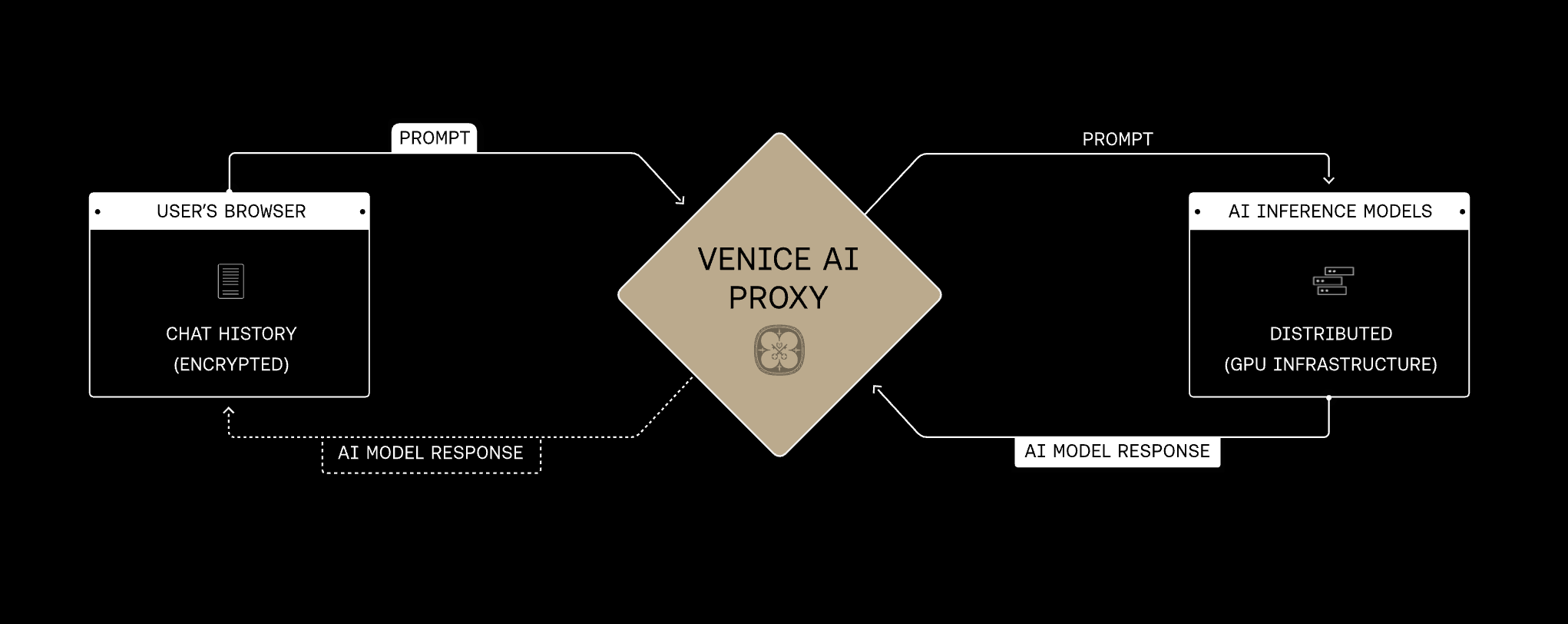
Datenschutz-Architektur
Der Venice-Proxy ist die gemeinsame Grundlage für jeden Datenschutzmodus. Anfragen laufen über HTTPS/TLS durch Venice und werden weitergeleitet, ohne dass Venice Prompt- oder Antwortinhalte speichert. Der Datenschutzmodus des ausgewählten Modells bestimmt, was als Nächstes auf der Provider- oder Modell-Laufzeitebene passiert. Venice präsentiert Modell-Datenschutz in vier Modi. Sie bauen auf derselben Proxy-Grundlage auf und ergänzen schrittweise stärkere Schutzmechanismen — von der Verschleierung der Identität gegenüber dem Provider bis hin zur Ende-zu-Ende-Verschlüsselung von Prompts in eine verifizierte Enklave.Zunehmender Datenschutz
Anonymous
Identität gegenüber Provider verschleiert
Venice proxyt die Anfrage, ohne Ihre Venice-Identität an den Modellprovider zu senden. Der Prompt-Inhalt ist für diesen Provider jedoch weiterhin sichtbar.
Private
Zero Data Retention, vertraglich durchgesetzt
Prompt- und Antwortinhalte werden ausschließlich für die Inferenz verarbeitet und nach Abschluss der Anfrage nicht aufbewahrt.
TEE
Hardware-isolierte Inferenz
Unterstützte Modelle laufen innerhalb einer Trusted Execution Environment mit Unterstützung für Remote Attestation.
E2EE
Ende-zu-Ende-verschlüsselt in eine verifizierte TEE
Ihr Client verschlüsselt den Prompt vor dem Senden. Venice leitet Ciphertext weiter, und nur die verifizierte TEE entschlüsselt ihn.
/models-Endpoint nennt Ihnen die Datenschutzstufe jedes Modells. Modelle, die als anonymized gekennzeichnet sind, sind Anonymous-Modelle, und Modelle, die als private gekennzeichnet sind, sind Private-Modelle. TEE und E2EE werden separat in den Capabilities des Modells angezeigt, z. B. als supportsTeeAttestation und supportsE2EE.
Implementierungsdetails finden Sie im TEE-&-E2EE-Modelle-Leitfaden.
TEE und E2EE
TEE- und E2EE-Modelle fügen kryptografische und hardwaregestützte Kontrollen zusätzlich zum Venice-Standardansatz ohne Inhaltsspeicherung hinzu.TEE verwenden, wenn
Sie möchten, dass das Modell innerhalb einer attestierten Hardware-Enklave läuft, Ihr Client aber Klartext-Prompts über den normalen API-Request senden kann.
E2EE verwenden, wenn
Sie möchten, dass Prompts verschlüsselt sind, bevor sie Ihren Client verlassen, und nur innerhalb einer verifizierten TEE entschlüsselt werden.
/chat/completions mit E2EE-fähigen Modellen. Ihr Client muss Attestation abrufen, Nonce und Enklave-Evidence verifizieren, user- und system-Nachrichten verschlüsseln, die X-Venice-TEE-*-Header senden, die Antwort streamen sowie den Antwortinhalt verifizieren/entschlüsseln.
E2EE deaktiviert außerdem Funktionen, die Klartext außerhalb der Enklave benötigen, wie Web Search, Memory, Zusammenfassungen, einige Tool-Flows und andere serverseitige Verarbeitung.
Modellauswahl
Verwenden Sie/models, um vor dem Senden einer Anfrage zu sehen, welche Datenschutz-Schutzmechanismen jedes Modell unterstützt.
Jedes Modell hat zwei relevante Felder:
model_spec.privacyzeigt den Basis-Datenschutzmodus des Modells:anonymized: Venice verbirgt Ihre Identität vor dem Provider, der Provider kann den Prompt jedoch noch sehen.private: Venice leitet die Anfrage über Zero-Data-Retention-Infrastruktur weiter.
model_spec.capabilitieszeigt, ob das Modell stärkere Schutzmechanismen unterstützt:supportsTeeAttestation: Das Modell kann innerhalb einer verifizierbaren Trusted Execution Environment laufen.supportsE2EE: Das Modell kann clientverschlüsselte Prompts akzeptieren, die nur innerhalb der TEE entschlüsselt werden.
private für Zero Data Retention, wählen Sie tee: true für hardwaregestützte Isolation und wählen Sie e2ee: true, wenn Sie Prompts verschlüsselt benötigen, bevor sie Ihren Client verlassen.