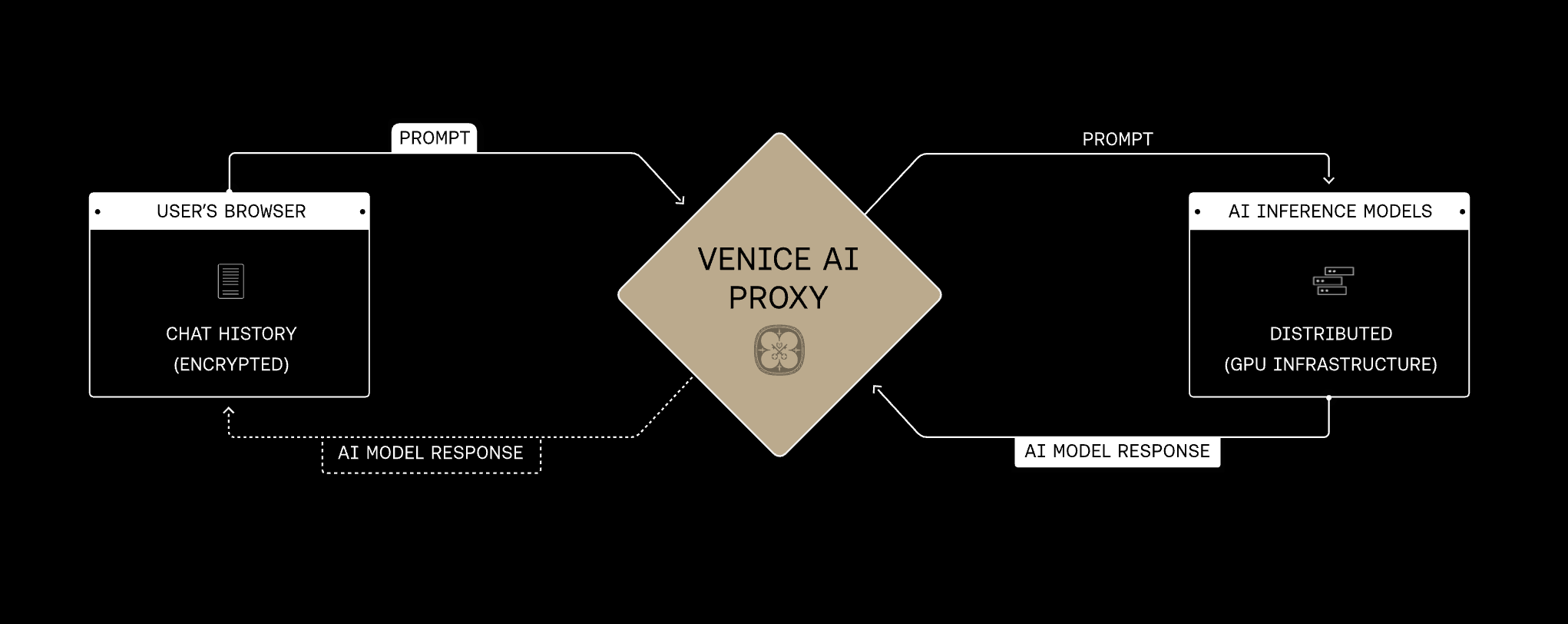
L’unico modo per ottenere una privacy utente ragionevole è evitare di raccogliere queste informazioni in primo luogo. È più difficile dal punto di vista ingegneristico, ma riteniamo sia l’approccio corretto.L’API Venice replica la stessa architettura di privacy backend della piattaforma Venice: le richieste passano attraverso il proxy Venice su connessioni cifrate, Venice non memorizza né registra il contenuto di prompt e risposte per l’inferenza normale e ciascun modello selezionato aggiunge una delle quattro modalità di privacy al livello di runtime: Anonymous, Private, TEE o E2EE.
Architettura di privacy
Il proxy Venice è la base condivisa per ogni modalità di privacy. Le richieste passano attraverso Venice via HTTPS/TLS e vengono inoltrate senza che Venice memorizzi il contenuto di prompt o risposte. La modalità di privacy sul modello selezionato determina cosa accade successivamente a livello di provider o di runtime del modello. Venice presenta la privacy dei modelli in quattro modalità. Si basano sulla stessa fondazione di proxy e aggiungono protezioni progressivamente più forti, dall’oscurare l’identità al provider fino a cifrare i prompt end-to-end verso un enclave verificato.Protezione della privacy crescente
Anonymous
Identità nascosta al provider
Venice inoltra la richiesta senza inviare la tua identità Venice al provider del modello. Il contenuto del prompt rimane visibile a quel provider.
Private
Zero data retention, garantita contrattualmente
Il contenuto di prompt e risposte viene elaborato solo per l’inferenza e non viene conservato dopo il completamento della richiesta.
TEE
Inferenza isolata via hardware
I modelli supportati vengono eseguiti all’interno di un Trusted Execution Environment con supporto alla remote attestation.
E2EE
Crittografia end-to-end verso un TEE verificato
Il tuo client cifra il prompt prima di inviarlo. Venice inoltra il ciphertext e solo il TEE verificato lo decifra.
/models ti indica il livello di privacy di ciascun modello. I modelli contrassegnati come anonymized sono modelli Anonymous e quelli contrassegnati come private sono modelli Private. TEE ed E2EE vengono mostrati separatamente nelle capacità del modello, come supportsTeeAttestation e supportsE2EE.
Per i dettagli di implementazione, consulta la guida ai modelli TEE & E2EE.
TEE ed E2EE
I modelli TEE ed E2EE aggiungono controlli crittografici e supportati da hardware oltre all’approccio predefinito di Venice di non conservare i contenuti.Usa TEE quando
Vuoi che il modello venga eseguito all’interno di un enclave hardware attestato, ma il tuo client può inviare i prompt in chiaro sulla normale richiesta API.
Usa E2EE quando
Vuoi che i prompt siano cifrati prima di lasciare il tuo client e decifrati solo all’interno di un TEE verificato.
/chat/completions con modelli abilitati a E2EE. Il tuo client deve recuperare l’attestation, verificare il nonce e l’evidenza dell’enclave, cifrare i messaggi user e system, inviare gli header X-Venice-TEE-*, eseguire lo streaming della risposta e verificare/decifrare il contenuto della risposta.
E2EE disabilita anche le funzionalità che richiedono testo in chiaro al di fuori dell’enclave, come web search, memoria, riassunti, alcuni flussi di tool e altre elaborazioni lato server.
Scegliere un modello
Usa/models per vedere quali protezioni di privacy supporta ciascun modello prima di inviare una richiesta.
Ogni modello ha due campi rilevanti:
model_spec.privacyindica la modalità di privacy di base del modello:anonymized: Venice nasconde la tua identità al provider, ma il provider può comunque vedere il prompt.private: Venice instrada la richiesta tramite infrastruttura zero-data-retention.
model_spec.capabilitiesindica se il modello supporta protezioni più forti:supportsTeeAttestation: il modello può essere eseguito all’interno di un Trusted Execution Environment verificabile.supportsE2EE: il modello può accettare prompt cifrati dal client che vengono decifrati solo all’interno del TEE.
private per zero data retention, scegli tee: true per l’isolamento basato su hardware e scegli e2ee: true quando hai bisogno che i prompt siano cifrati prima di lasciare il tuo client.